对于微服务来说,分布式架构将是研究的重点,本篇继续介绍分布式架构的一些概念!
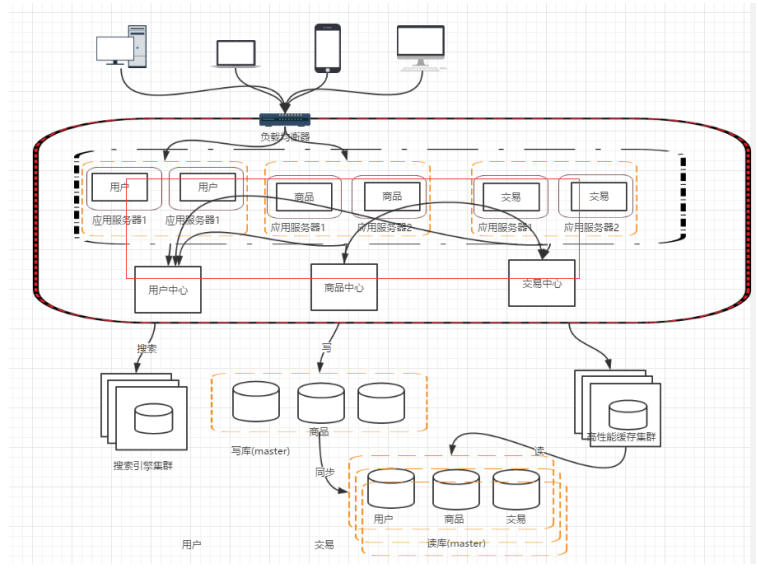
阶段七,数据库的水平/垂直拆分
我们的网站演进的变化过程,交易、商品、用户的数据都还在同一个数据库中,尽管采取了增加缓存,读写分离的方式,但是随着数据库的压力持续增加,数据库的瓶颈仍然是个最大的问题。因此我们可以考虑对数据的垂直拆分和水平拆分
垂直拆分:把数据库中不同业务数据拆分到不同的数据库:
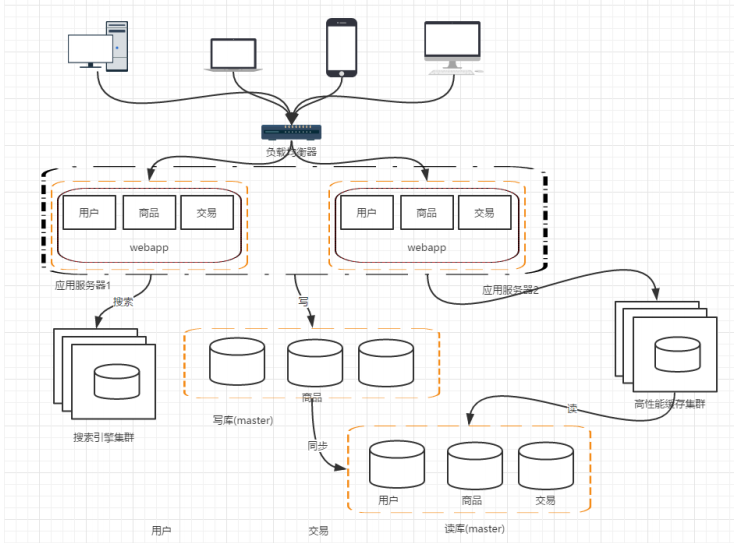
水平拆分:把同一个表中的数据拆分到两个甚至跟多的数据库中,水平拆分的原因是某些业务数据量已经达到了单个数据库的瓶颈,这时可以采取讲表拆分到多个数据库中:
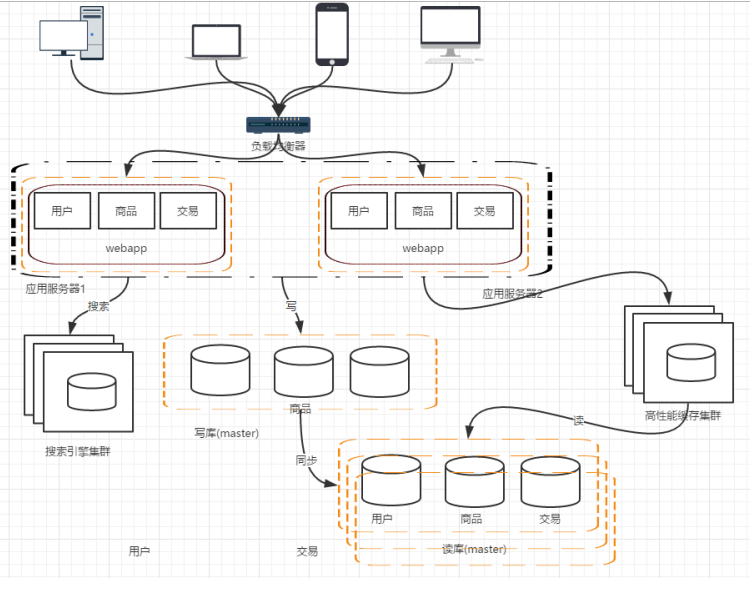
阶段八,应用的拆分
随着业务的发展,业务越来越多,应用的压力越来越大。工程规模也越来越庞大。这个时候就可以考虑讲应用拆分,按照领域模型讲我们的用户、商品、交易拆分成多个子系统:
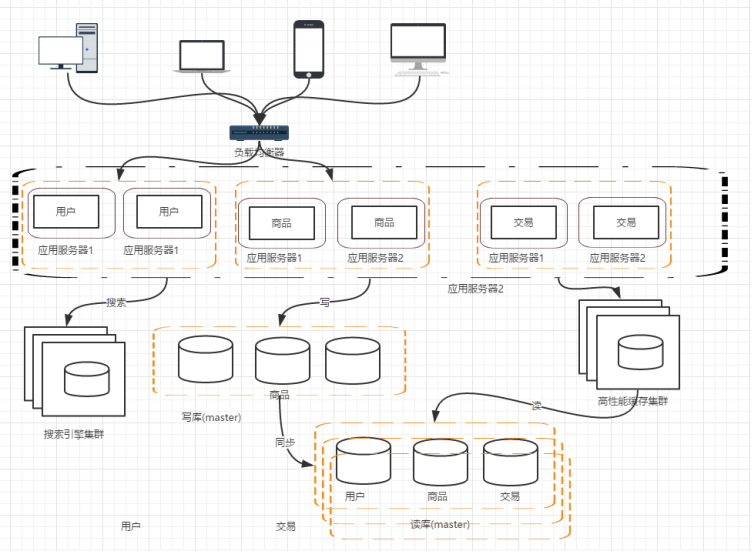
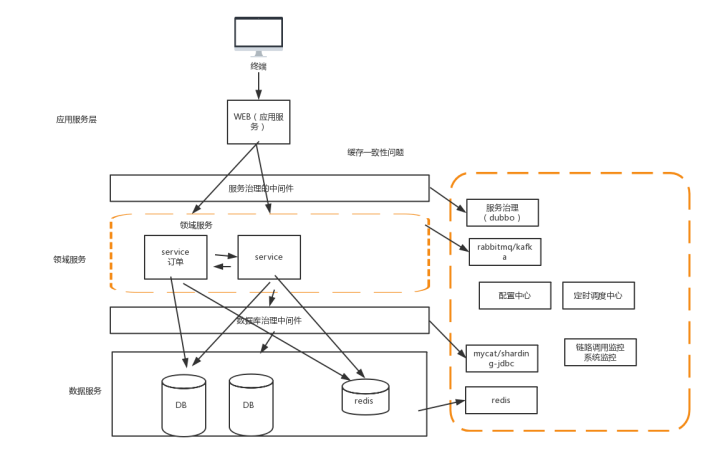
这样拆分以后,可能会有一些相同的代码,比如用户操作,在商品和交易都需要查询,所以会导致每个系统都会有用户查询访问相关操作。这些相同的操作一定是要抽象出来,否则就会是一个坑。所以通过走服务化路线的方式来解决:
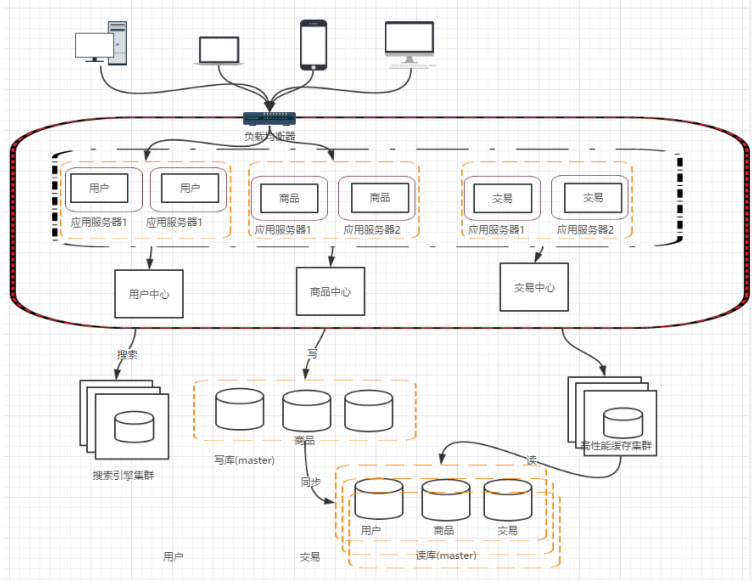
那么服务拆分以后,各个服务之间如何进行远程通信呢?
通过 RPC 技术,比较典型的有:webservice、hessian、http、RMI等等 前期通过这些技术能够很好的解决各个服务之间通信问题,but,互联网的发展是持续的,所以架构的演变和优化还在持续。
总结详解:
分布式系统的难点
毫无疑问,分布式系统对于集中式系统而言,在实现上会更加复杂。分布式系统将会是更难理解、设计、构建 和管理的,同时意味着应用程序的根源问题更难发现。
- 三态
在集中式架构中,我们调用一个接口返回的结果只有两种,成功或者失败,但是在分布式领域中,会出现“超时”这个状态。
- 分布式事务
这是一个老生常谈的问题,我们都知道事务就是一些列操作的原子性保证,在单机的情况下,我们能够依靠本机的数据库连接和组件轻易做到事务的控制,但是分布式情况下,业务原子性操作很可能是跨服务的,这样就导致了分布式事务,例如 A和 B 操作分别是不同服务下的同一个事务操作内的操作,A 调用 B,A 如果可以清楚的知道 B 是否成功提交从而控制自身的提交还是回滚操作,但是在分布式系统中调用会出现一个新状态就是超时,就是 A 无法知道 B 是成功还是失败,这个时候 A是提交本地事务还是回滚呢?其实这是一个很难的问题,如果强行保证事务一致性,可以采取分布式锁,但是那样会增加系统复杂度而且会增大系统的开销,而且事务跨越的服务越多,消耗的资源越大,性能越低,所以最好的解决方案就是避免分布式事务。
还有一种解决方案就是重试机制,但是重试如果不是查询接口,必然涉及到数据库的变更,如果第一次调用成功但是没返回成功结果,那调用方第二次调用对调用方来说依然是重试,但是对于被调用方来说是重复调用,例如 A 向 B 转账,A-100,B + 100,这样会导致 A 扣了 100,而 B 增加 200。这样的结果不是我们期望的,因此需在要写入的接口做幂等设计。多次调用和单次调用是一样的效果。通常可以设置一个唯一键,在写入的时候查询是否已经存在,避免重复写入。但是幂等设计的一个前提就是服务是高可用,否则无论怎么重试都不能调用返回一个明确的结果调用方会一直等待,虽然可以限制重试的次数,但是这已经进入了异常状态了,甚至到了极端情况还是需要人肉补偿处理。其实根据 CAP 和 BASE 理论,不可能在高可用分布式情况下做到一致性,一般都是最终一致性保证。
- 负载均衡
每个服务单独部署,为了达到高可用,每个服务至少是两台机器,因为互联网公司一般使用可靠性不是特别高的普通机器,长期运行宕机概率很高,所以两台机器能够大大降低服务不可用的可能性,这正大型项目会采用十几台甚至上百台来部署一个服务,这不仅是保证服务的高可用,更是提升服务的 QPS,但是这样又带来一个问题,一个请求过来到底路由到哪台机器?路由算法很多,有 DNS 路由,如果 session 在本机,还会根据用户 id 或则 cookie 等信息路由到固定的机器,当然现在应用服务器为了扩展的方便都会设计为无状态的,session 会保存到专有的 session 服务器,所以不会涉及到拿不到 session 问题。那路由规则是随机获取么?这是一个方法,但是据我所知,实际情况肯定比这个复杂,在一定范围内随机,但是在大的范 围也会分为很多个域,例如如果为了保证异地多活的多机房,夸机房调用的开销太大,肯定会优先选择同机房的服务,这个 要参考具体的机器分布来考虑。
- 一致性
数据被分散或者复制到不同的机器上,如何保证各台主机之间的数据的一致性将成为一个难点。
- 故障的独立性
分布式系统由多个节点组成,整个分布式系统完全出问题的概率是存在的,但是在时间中出现更多的是某个节点出问题,其他节点都没问题。这种情况下我们实现分布式系统时需要考虑得更加全面些。