Mysql!
概览
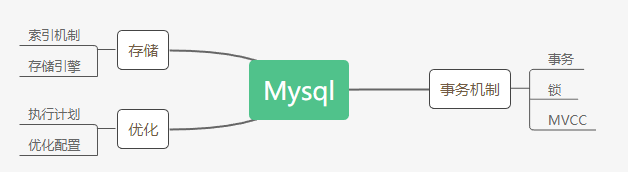
掌握mysql大致分三块:存储、事务以及优化;
存储
索引
为了从数据集中最快检索到有效数据,一般都会建立索引,所以正确建立合适的索引成为关键!
mysql中使用B+树建立索引,它的优势:
1 减少存储引擎需要扫描的数据量
2 将随机IO转换成顺序IO
3 帮助我们在进行分组、排序的时候使用临时表
- 为什么B+树可以有这些优势呢?
B+树只有叶子节点存储数据,单个节点存储的关键字多,有效的减少了IO操作的次数
叶子节点存储数据天然有序,使用B+树更加稳定,查询效率可算
- 使用B+树对程序员建立索引的启示
有效的建立索引,不要建立冗余索引
索引定义最小宽度
语句最左匹配会使用到索引
索引要建立在离散度高的列上
不要使用select * ,表明字段在查找的时候,会覆盖索引,提高查询效率
使用查看执行计划检验索引使用的好坏
存储引擎
存储引擎可定义在表上,5.7版本之后默认使用innodb存储引擎,之前默认使用myisam,都是采用可插拔方式使用。
CSV存储引擎使用在数据快速导入导出,表格直接转换成CSV
Archive存储引擎占用空间在最少,100万数据占用3M存储,而innodb占大约27M。
Memory存储引擎,主要存储在内存中大小默认16M,缓存存储引擎,也可用于临时表,热数据
Myisam:文件MYD、MYI分别存储数据和索引,Frm表定义文件,表级锁、不支持事务
Innodb:支持事务ACID,行级锁,以聚集索引存储数据,支持外键保证数据完整性(不建议使用)
事务机制
事务
ACID:原子性、一致性、隔离性、持久性;
由于并发带来了事务性,那事务带来的实际问题:
脏读、可重复读、幻读三个问题;
为了解决或者容忍它带来的问题,mysql定义了四种隔离级别:
RU:未提交读(啥也没解决)
RC:提交读(解决脏读)
RR:可重复读(解决重复读)(innodb中解决了幻读问题,所以nb)
serializable串行化(都解决了)
锁
InnoDB的行锁是通过加在了索引项上来实现的,只有通过索引条件进行的检索才使用行级锁,否则也是表锁,锁住表中所有记录;
根据锁住的类型分为:
- 共享锁(行锁):s锁,又称读锁
只能读不能修改,加锁方式,在语句后+ LOCK IN SHARE MODE;
- 排它锁(行级):X锁,又称写锁
只有获取到了才能读取或者修改,加锁方式,增删改默认就加了,读语句+FOR UPDATE;
- 意向共享锁IS(表锁):其实就是表的标志位,提供给其他的调用者查看是否该表已经有s锁了
即一个数据行加共享锁前必须先取得该表的IS锁,意向共享锁之间是可以相互兼容的
- 向排他锁IX表锁):其实就是表的标志位,提供给其他的调用者查看是否该表已经有x锁了
即一个数据行加排他锁前必须先取得该表的IX锁,意向排它锁之间是可以相互兼容的
意向锁(IS、 IX)是InnoDB数据操作之前自动加的, 不需要用户干预,意义:当事务想去进行锁表时, 可以先判断意向锁是否存在, 存在时则可快速返回该表不能启用表锁
- 自增锁:提示就是自增id不连续的问题,给自增id的具体一个数据加了锁
根据锁的算法又划分:
- 记录锁
根据索引项查找数据项,锁住具体某一条数据项
- 间隙锁
根据索引项查找数据项,没有命中数据时候,根据左开右开建立区间,将假设命中数据区间锁住,GAP锁仅仅存在在RR事务级别中
- 临界锁
当索引查找的是范围时,根据左开右闭建立区间,将命中数据区间和下个区间锁住,这个也是RR为啥能解决幻读的问题,因为这些区间在叶子节点存储数据是有序的,锁住后,不能修改了。
通过锁很大程度上解决了事务的一部分问题,但并没有真正解决所有问题。
MVCC(并发多版本控制)
在并发事务中,为了提高效率引入了MVCC,避免写的时候,无法读引起的并发问题;
MVCC中默认的每个表有DB_TRX_ID数据行的版本号列和DB_ROLL_PT删除版本号列
- 具体如何操作
插入数据,将本事务的版本号赋值给【数据行的版本号】;
如果删除以索引为查找的某行时,将该删除行复制一条数据放在表中,该事务的操作的版本号赋值给复制的这条数据的【删除版本号列】
那么,(本事务未提交)在另一个事务中查找时,会查找出来,数据版本小于当前版本的数据行(确保读取的是以前存在的,要么是自己修改或插入过得),查找删除版本大于当前版本或者null的行(确保查找出来的记录是在事务开启之前没有被删除的)。
- 问题
及时加了MVCC,依然没有解决脏读问题,因为只解决了先查后改的问题,没有解决先改后查
-
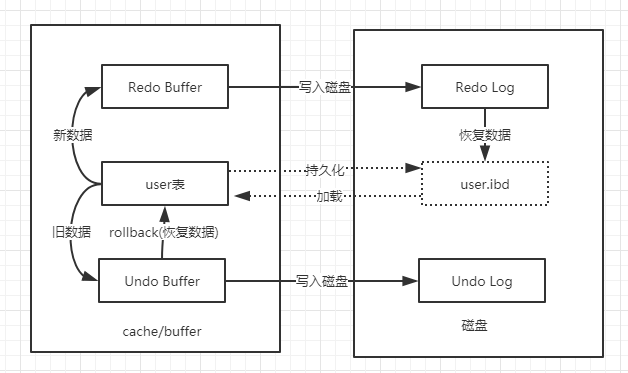
为了真正解决问题,提出了Undo log+ Redo log
-
Undo log:
为了实现事务的原子性而出现的产物,指事务开始之前, 在操作任何数据之前,首先将需操作的数据备份到一个地方 (Undo Log),以撤销操作为目的, 返回指定某个状态的操作,Undo 中的数据可作为数据旧版本快照供其他并发事务进行快照读
解释一下:快照读和当前读
快照读:SQL读取的数据是快照版本, 也就是历史版本, 普通的SELECT就是快照读
innodb快照读, 数据的读取将由 cache(原本数据) + undo(事务修改过的数据) 两部分组成
当前读:SQL读取的数据是最新版本。 通过锁机制来保证读取的数据无法通过其他事务进行修改UPDATE、 DELETE、 INSERT、 SELECT … LOCK IN SHARE MODE、 SELECT … FOR UPDATE都是当前读
-Redo log:
不是随着事务的提交才写入的, 而是在事务的执行过程中, 便开始写入redo 中。 具体的落盘策略可以进行配置,指事务中操作的任何数据,将最新的数据备份到一个地方 (Redo Log), 以恢复操作为目的, 重现操作;为了实现事务的持久性而出现的产物
Redo Log实现事务持久性:防止在发生故障的时间点, 尚有脏页未写入磁盘, 在重启mysql服务的时候, 根据redolog进行重做, 从而达到事务的未入磁盘数据进行持久化这一特性。
Redo log的位置:可通过innodb_log_group_home_dir 配置指定目录存储
Redo buffer 持久化Redo log的策略选择0,1,2
大概的意思是:
优化
Mysql使用半双工进行通信-没必要将消息切成块传输,而是增量传输,提高效应效率
msyql一般会先对sql语句通过查询优化器进行优化
如:等价变换规则,基于联合索引,调整条件位置等
优化count/min/max函数,min只需找叶子节点的最左侧就行,max只需找最右侧就行,myisam天然就有count支持
覆盖索引
子查询优化
提前终止查询:如limit
in优化,使用二分查找,所以别用or用in
执行计划
使用explain可以查看某条查询语句的执行计划
- 如果有多条执行计划,根据id的序列号,执行顺序是:
id相同,由上向下执行
id不同,id越大约先执行
id很多,根据id越大组执行,同组由上至下
-
阅读执行计划
- select_type(查询类型,包括普通、联合、子查询)
SIMPLE: 简单的select查询, 查询中不包含子查询或者union
PRIMARY: 查询中包含子部分, 最外层查询则被标记为primary
SUBQUERY/MATERIALIZED: SUBQUERY表示在select 或 where列表中包含了子查询
MATERIALIZED表示where 后面in条件的子查询
UNION: 若第二个select出现在union之后, 则被标记为union;
UNION RESULT: 从union表获取结果的select
- table(所及到的表)
一般是表名或者别名
<unionM,N> 由id为m,n查询union产生的结果
由Id为N查询生成的结果 - type(最重要的) system:表只有一行记录,就是系统表,基本不会出现 const:通过索引一次就查找到了,const用于比较primary key 或者unique索引 eq_ref:唯一索引扫描,对于每个索引键,表中只有一条记录与之匹配,常见主键或者唯一索引 ref:非唯一性索引,返回匹配某个单独值得所有行,本质也是一种索引访问 range:只检索给定范围的行,使用一个索引来选择行 index:Full Index Scan ,索引全表扫描,把索引从头到尾部扫一遍 All:遍历全表以找到所有匹配行 - possible_keys (查询可能会用到的索引) - key(实际使用的索引,如果为NULL,则没有使用索引) - rows(大致为了找到行而扫描的行数) - filtered(返回结果行与读取行数百分比,越大越好) -Extra Using filesort :使用外部文件排序,而不是使用表内索引排序读取 Using temporary:使用临时表保存中间结果,常见order by或者group by Using index: 表示使用了覆盖索引 Using where:使用了where过滤条件 select tables optimized away:基于索引优化MIN/MAX操作或者MyISAM存储引擎优化COUNT()操作, 不必等到执行阶段在进行计算, 查询执行计划生成的阶段即可完成优化
优化配置
全局配置文件配置
- max_connections:最大连接数的配置
取决于系统句柄数的配置:如/etc/security/limits.conf,使用ulimit -a 可以查看
除了系统限制外,还受限于mysql句柄限制:如/usr/lib/systemd/system/mysqld.service
-
sort_buffer_size 每一个conntion排序缓存区大小,建议256K(默认值)-> 2M之内
-
join_buffer_size connection关联查询缓冲区大小,建议256K(默认值)-> 2M之内
上述配置4000连接占用内存:
4000*(0.256M+0.256M) = 2G
- Innodb_buffer_pool_size(innodb buffer/cache的大小默认128M)
数据缓存、索引缓存、缓冲数据、内部结构
大的缓冲池可以减小多次磁盘I/O访问相同的表数据以提高性能
参考计算公式:Innodb_buffer_pool_size = (总物理内存 - 系统运行所用 - connection 所用) * 90%
-
wait_timeout 服务器关闭非交互连接之前等待活动的秒数
-
innodb_open_files 限制Innodb能打开的表的个数
-
innodb_lock_wait_timeout InnoDB事务在被回滚之前可以等待一个锁定的超时秒数
数据库设计的优化
参见:58同城30条
常用语句
show create table bas_file;//查看创建表的语句,发现 ENGINE=InnoDB DEFAULT
show variables like ‘datadir’;//查看数据存储位置
show full processlist / show processlist;//查看连接及状态
kill [id]; //杀死某连接
show variables like ‘query_cache%’;//查询缓存情况
explain select * … ;//查看执行计划
begin / start transaction ;开始事务
commit / rollback ;//事务提交或回滚
set global autocommit = ON/OFF;//是否执行事务
mysql –help ;//寻找配置文件的位置和加载顺序
注意:
全局参数的设定对于已经存在的会话无法生效
会话参数的设定随着会话的销毁而失效
全局类的统一配置建议配置在默认配置文件中, 否则重启服务会导致配置失效